Git as a tool !

Hello Peers! Today let's talk about git and why the need of it be!
Git basically is a form of code management , version control system which allows us to collaborate with different developers and codes.
With Git, we can keep a track of all older versions of any files and can revert back to them in case the latest version has some undying issues to be fixed.
Code management being the most practical use of git, it allows users to work on different segments of the problem and then these individual works can be collaborated via merge to a single version of file.
Version Control System (VCS) and its types:
Version control is the system which tracks all the changes that happened to a file over the time so as we can recall the needed version later on . It allows the file to revert back to previous states, compare over time, track the user who made those changes and also to keep a track of timing at which the change was introduced. The VCS is of 2 types:
1. Centralized version control system :
CVCS works on a central repository to store all files and enable team collaborations, which can only be accessed directly via a system of central server.
However convenient may it seem, it does have major drawbacks like the need to be connected to a local network at times in order to perform any action. And, if the central system goes down, so does the whole network of it, leading to loss of all repositories and work progress as well.

2. Distributed version control system :
As the diagram below suggests, the DVCS does not rely on a central server to store all the versions of the file, instead it makes a clone or copy of the main repository on their local drive as a local repository over which he makes all the needed changes without affecting the main repository.
They can update their local repositories with new data from the central server by an operation called “pull” and affect changes to the main repository by an operation called “push” from their local repository.
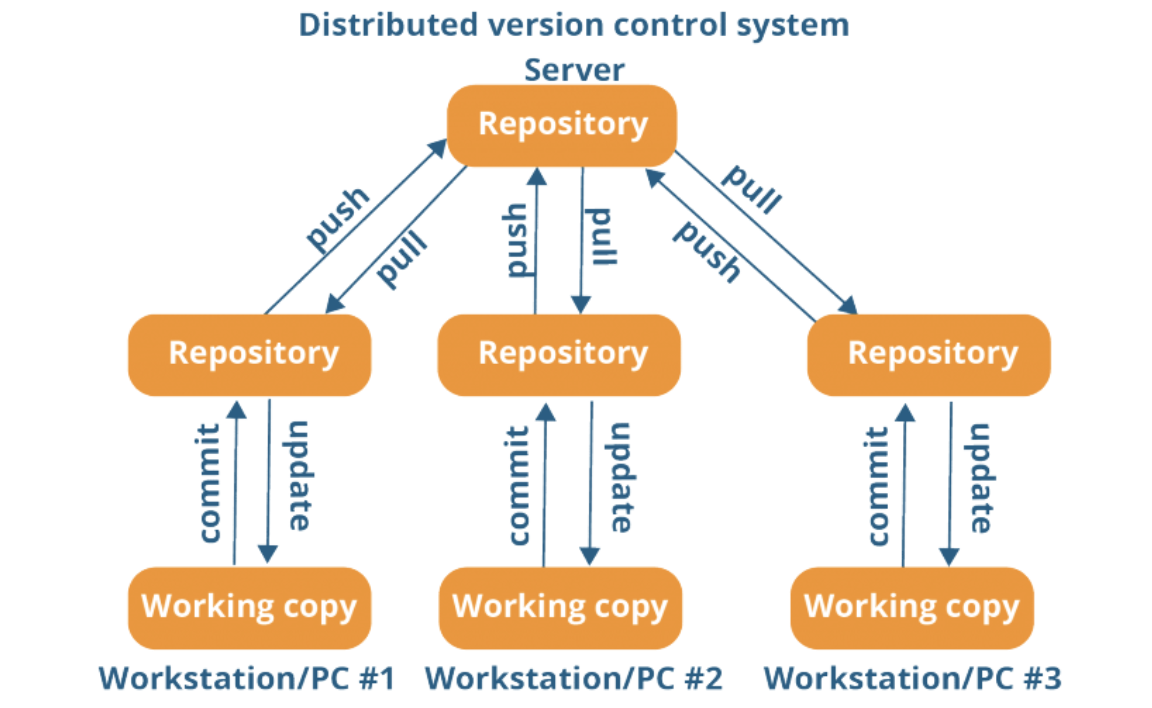
Why DVCS over CVCS:
Better collaboration: In a DVCS, every developer has a full copy of the repository, including the entire history of all changes. This makes it easier for developers to work together, as they don't have to constantly communicate with a central server to commit their changes or to see the changes made by others.
Improved speed: Because developers have a local copy of the repository, they can commit their changes and perform other version control actions faster, as they don't have to communicate with a central server.
Greater flexibility: With a DVCS, developers can work offline and commit their changes later when they do have an internet connection. They can also choose to share their changes with only a subset of the team, rather than pushing all of their changes to a central server.
Enhanced security: In a DVCS, the repository history is stored on multiple servers and computers, which makes it more resistant to data loss. If the central server in a CVCS goes down or the repository becomes corrupted, it can be difficult to recover the lost data.
Now, we will check the 3 stage architecture of git:
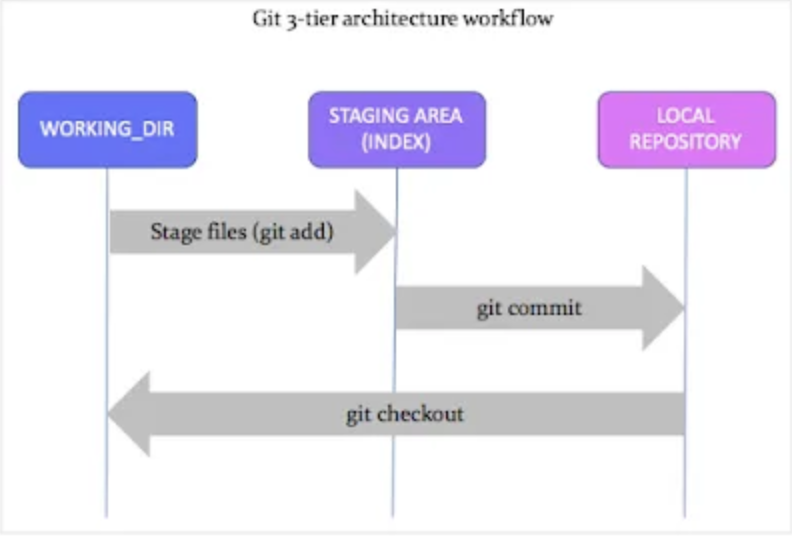
- Working Directory: Place where we can see the files and do the modification (git init).
- Staging area: This is the temporary storage area where all the changes made locally is stored. This allows you to review your changes before committing (git add).
- Repository: This is the final storage area where all changes are stored after the commit. This contains the complete history of changes made to the files and also the user and timestramp of the changes (git commit).
How to make a git repository on your server:
Let's make a directory on our server named GitforDevOps then we will initialise git on it via "git init" command. Let's have a look:

Inside the GitforDevOps folder we will now create a file commands.txt where we will be practicing different git commands.
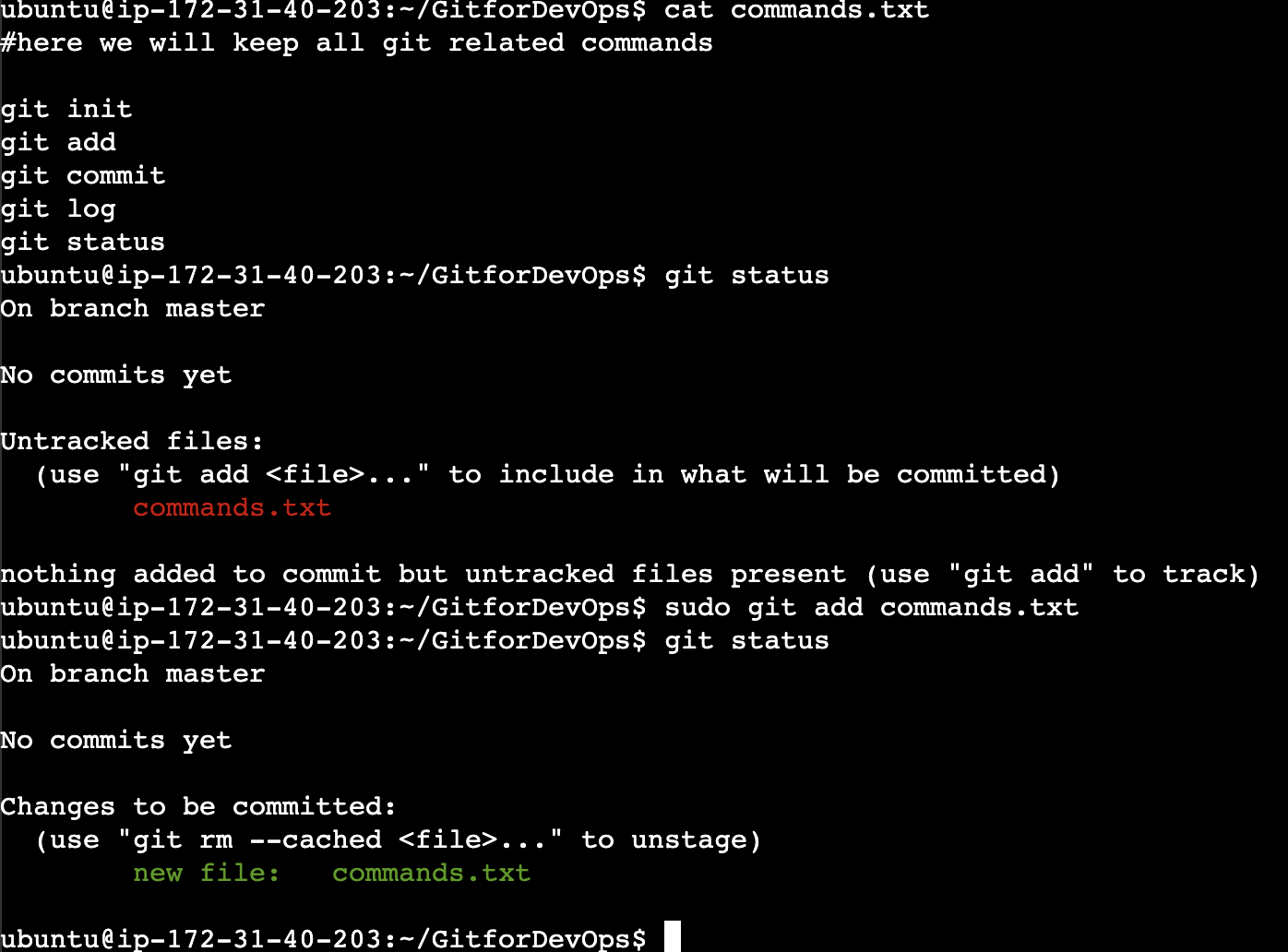
As we can see the results of git status before and after git add, we can clearly see the comment before staging as "Untracked files:" which means that file is still not tracked i.e., no version of it is stored currently on the repository.
When we do "git add" (stage the file), the change in colour for commands.txt where green colour indicates now the staged files i.e., the file is now ready to be committed for the changes made in it. (check the above snip)
As soon as we commit the file, we can see the status as "nothing to commit, working tree clean" which means our change has been now stored on repository and now posed as version of a file on it.

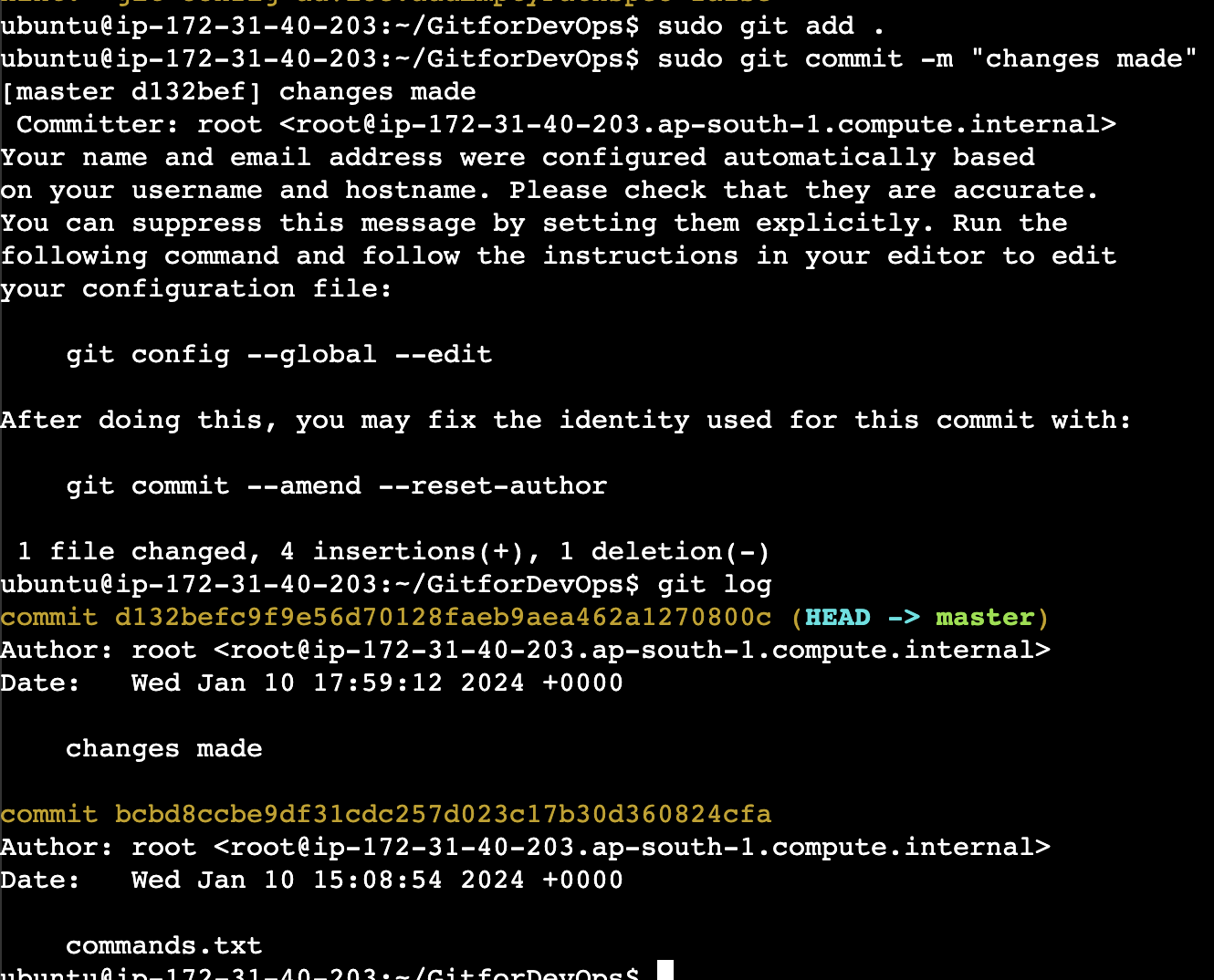
Checking the log for git, we get:

As we can now see the log file for commands.txt is now committed, what if we want that change to be removed

but since the whole file is now stored on VCS, we can still retrieve the file, let us check how :

This restore feature has a very practical use in our day to day practice wherein we have to recover some files which were by some reason removed previously, this concept is not present on any file system i.e., if a file is once deleted from from the file system we can not by any mean retrieve it back.
Now let us see what happens to the status of file if we edit it post committing it:

now as mention we will have to stage and commit the whole file again and this happens after each modifications made to the file.
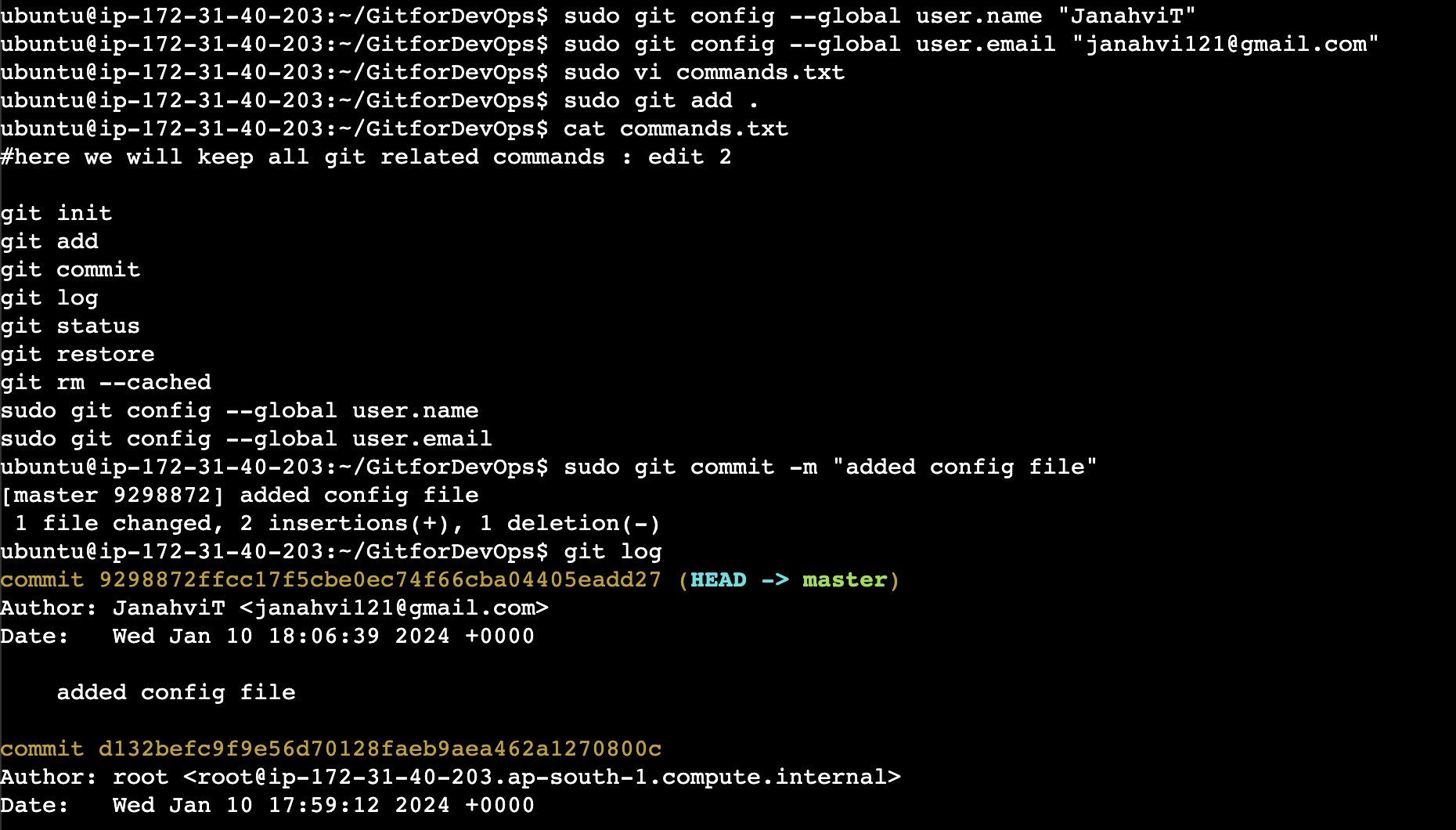
How to configure git:
Now, if we want to change the name of author and email of the commit, we have to configure the changes accordingly. Look below snip for reference:
On that note, let the learning continue .
Next we will be covering pull, push and fetch usage from GitHub.
Stay tuned folks!!



